Модели глубокого обучения стали движущей силой «революции» ИИ последних двух лет, предоставив нам доступ ко всему: от броских новых поисковых инструментов до нелепых генераторов изображений. Но эти модели, какими бы удивительными они ни были, обладают способностью эффективно запоминать обучающую информацию и повторять ее дословно, что является потенциальной проблемой. Мало того, после обучения крайне сложно по-настоящему удалить данные из модели, такой как GPT-4. Допустим, ваша модель МО была случайно обучена на данных, содержащих чьи-то банковские реквизиты, как вы можете «отучить» модель, не начав с нуля?
К счастью, есть область исследований, работающая над решением. Машинное разучение — развивающаяся, но все более интересная область исследований, в которую начинают вмешиваться некоторые серьезные игроки. Так что же такое машинное разучение, и могут ли LLM когда-либо по-настоящему забыть то, что им когда-то дали?
Как обучаются модели
Для любой большой модели LLM или ML необходим большой набор данных.

Источник: Lenovo
Как мы уже говорили, модели машинного обучения используют большой объем обучающих данных (иногда называемых корпусом) для генерации весов модели, т. е. для предварительной подготовки модели. Именно эти данные напрямую определяют, что модель способна «знать». После этой стадии предварительной подготовки модель совершенствуется для улучшения ее результатов. В случае моделей LLM-трансформеров, таких как ChatGPT, это усовершенствование часто принимает форму RLHF (обучение с подкреплением и обратной связью с человеком), где люди предоставляют прямую обратную связь модели для улучшения ее ответов.
Обучение одной из этих моделей требует чрезвычайных затрат. В отчете The Information, опубликованном в начале этого года, приводятся ежедневные эксплуатационные расходы ChatGPT в размере около 700 000 долларов. Обучение этих моделей требует огромной вычислительной мощности GPU, которая одновременно и дорога, и все более дефицитна.
Введите машинное отучивание
А что, если мы захотим удалить часть обучающих данных?

Машинное отучивание на самом деле то, как оно звучит. Можем ли мы удалить определенный фрагмент данных из уже обученной модели? Машинное отучивание — это развивающаяся (Google недавно объявила о своей первой задаче по машинному отучению) чрезвычайно важная область исследований для глубокого обучения. Хотя это может показаться простым, это далеко не так просто. Тривиальный ответ — переобучить модель, за исключением набора данных, который нужно удалить. Однако, как мы уже упоминали, это часто непомерно дорого и/или требует много времени. Для моделей федеративного обучения, ориентированных на конфиденциальность, существует вторая проблема — исходный набор данных может быть больше недоступен. Реальная цель машинного отучивания — создать модель, максимально приближенную к полностью переобученной модели, за вычетом проблемных данных, чтобы максимально приблизиться к полной переобученной модели, фактически не делая этого.
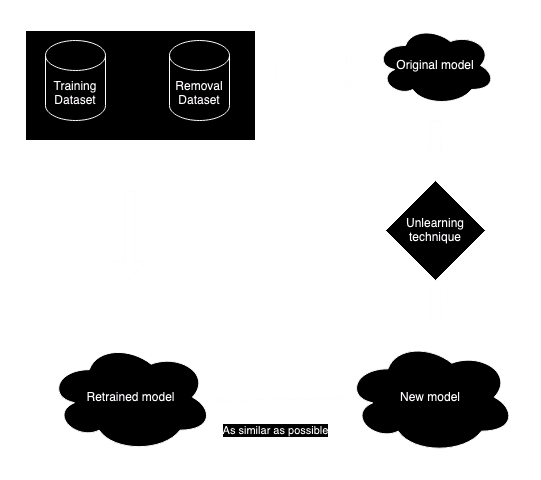
Воспроизведено из [1]
Если мы не можем переобучить модель, можем ли мы удалить определенные веса, чтобы помешать знанию моделей о целевом наборе данных? Вероятный ответ здесь также «нет». Во-первых, гарантировать, что целевой набор данных был полностью удален путем прямого вмешательства в модель, практически невозможно; вполне вероятно, что фрагменты целевых данных останутся. Во-вторых, влияние на общую производительность модели также трудно количественно оценить, и оно может иметь неблагоприятные последствия не только для общей производительности, но и для других конкретных областей знаний моделей. По этой причине (и другим) обычно считается нецелесообразным напрямую удалять элементы из модели.
Этот метод удаления определенных параметров модели иногда называют сдвигом модели.
Уже существуют методы отучения машин от обучения
Существует несколько существующих алгоритмов машинного отучения, которые можно в значительной степени разбить на несколько типов. Точное отучение пытается сделать выходные данные переобученной модели и исходной модели неразличимыми, за исключением набора данных, специфичного для отучения. Это самая экстремальная форма отучения, и она обеспечивает самую надежную гарантию того, что никакие нежелательные данные не могут быть извлечены. Сильное отучение реализовать проще, чем точное отучение, но требует только приблизительной неразличимости двух моделей. Однако это не гарантирует, что некоторая информация не останется в извлеченном наборе данных. Наконец, слабое отучение реализовать проще всего, но не гарантирует, что удаленные данные обучения больше не хранятся внутри. Вместе сильное и слабое отучение иногда называют приблизительным отучением.
Методы машинного отучения
Теперь это становится немного техническим, но мы рассмотрим некоторые общие методы машинного отучения. Точные методы отучения сложнее всего реализовать на больших LLM, и часто они лучше всего работают на простых структурированных моделях. Это может включать такие методы, как обратные ближайшие соседи, которые пытаются компенсировать удаление точки данных путем корректировки ее соседей. K-ближайшие соседи — это похожая идея, но удаляет точки данных на основе их близости к целевому биту данных, а не корректирует их. Другая распространенная идея — разделить набор данных на подмножества и обучить ряд частичных моделей, которые впоследствии можно объединить (часто это называется шардингом). Если необходимо удалить определенный бит данных, набор данных, который его содержит, можно обучить заново, а затем объединить с существующими наборами данных.

Более распространены приближенные методы отучения. Они могут включать инкрементальное обучение, которое строится поверх существующей модели для корректировки ее выходных данных и «отучения» данных. Это наиболее эффективно для небольших обновлений и удалений и является частью текущей тонкой настройки моделей. Методы на основе градиента похожи на RNN выше, в том, что они пытаются компенсировать удаленные точки данных путем отмены обновлений градиента, примененных во время обучения. Они могут быть точными, но часто требуют больших вычислительных затрат и испытывают трудности с более крупными моделями.
Существуют и другие методы, которые мы здесь не будем рассматривать, но, как правило, они предлагают некоторый компромисс между вычислительными затратами, точностью и тем, насколько хорошо они масштабируются для больших моделей.
Машинное отвыкание становится все более важной темой
«Ошибки» в обучающих данных могут стать более дорогостоящими

Источник: Unsplash
Машинное отучивание, вероятно, станет горячей темой в течение следующих нескольких лет, особенно с учетом того, что обучение LLM становится все более сложным и дорогим. Растет риск того, что регулирующие органы или судьи могут попросить создателей больших моделей удалить определенные фрагменты данных из их ИИ, будь то из-за лицензирования или нарушения авторских прав. Законодательство GDPR или «право быть забытым» уже существует в некоторых странах мира. Такие компании, как OpenAI, уже попали в серьезные споры, используя нелицензированные данные обучения из New York Times, а более широкое использование лицензированного пользовательского контента может вызвать постоянные проблемы вокруг права собственности на контент (как уже выяснил Stack Overflow). OpenAI также была втянута в споры, вытекающие из использования защищенных авторским правом произведений искусства в Интернете (как и многие другие) при обучении своих моделей, что породило совершенно новые дебаты о новых модификациях.
Отвыкание от обучения – это развивающаяся область
По мере того, как ландшафт ИИ замедляется с бешеной скорости прогресса в 2023 году, регулирующие органы начинают наверстывать упущенное в вопросах, связанных с обучением ИИ. Гонка за данными для обучения быстро превращает интернет во все более светское, разделенное место, как показала недавняя эксклюзивная сделка Google с Reddit. Проведут ли суды и регулирующие органы когда-либо достаточно жесткую черту, чтобы заставить переобучать и удалять данные из моделей после поверхностного уровня, нам еще предстоит увидеть. Но оставив в стороне последствия для конфиденциальности, машинное разучение обещает быть сложной, но полезной техникой, не только для забывания данных из моделей, но и для исправления ошибок в их обучающих данных в дальнейшем.

